![]()
Reliable Microsoft Azure DP-100 Dumps PDF Feb 09, 2022 Recently Updated Questions
Pass Your Microsoft DP-100 Exam with Correct 230 Questions and Answers
Microsoft DP-100 Exam Syllabus Topics:
| Topic | Details |
|---|---|
Manage Azure resources for machine learning (25-30%) | |
| Create an Azure Machine Learning workspace | - create an Azure Machine Learning workspace - configure workspace settings - manage a workspace by using Azure Machine Learning studio |
| Manage data in an Azure Machine Learning workspace | - select Azure storage resources - register and maintain datastores - create and manage datasets |
| Manage compute for experiments in Azure Machine Learning | - determine the appropriate compute specifications for a training workload - create compute targets for experiments and training - configure Attached Compute resources including Azure Databricks - monitor compute utilization |
| Implement security and access control in Azure Machine Learning | - determine access requirements and map requirements to built-in roles - create custom roles - manage role membership - manage credentials by using Azure Key Vault |
| Set up an Azure Machine Learning development environment | - create compute instances - share compute instances - access Azure Machine Learning workspaces from other development environments |
| Set up an Azure Databricks workspace | - create an Azure Databricks workspace - create an Azure Databricks cluster - create and run notebooks in Azure Databricks - link and Azure Databricks workspace to an Azure Machine Learning workspace |
Run Experiments and Train Models (20-25%) | |
| Create models by using the Azure Machine Learning Designer | - create a training pipeline by using Azure Machine Learning designer - ingest data in a designer pipeline - use designer modules to define a pipeline data flow - use custom code modules in designer |
| Run model training scripts | - create and run an experiment by using the Azure Machine Learning SDK - configure run settings for a script - consume data from a dataset in an experiment by using the Azure Machine Learning SDK - run a training script on Azure Databricks compute - run code to train a model in an Azure Databricks notebook |
| Generate metrics from an experiment run | - log metrics from an experiment run - retrieve and view experiment outputs - use logs to troubleshoot experiment run errors - use MLflow to track experiments - track experiments running in Azure Databricks |
| Use Automated Machine Learning to create optimal models | - use the Automated ML interface in Azure Machine Learning studio - use Automated ML from the Azure Machine Learning SDK - select pre-processing options - select the algorithms to be searched - define a primary metric - get data for an Automated ML run - retrieve the best model |
| Tune hyperparameters with Azure Machine Learning | - select a sampling method - define the search space - define the primary metric - define early termination options - find the model that has optimal hyperparameter values |
Deploy and operationalize machine learning solutions (35-40%) | |
| Select compute for model deployment | - consider security for deployed services - evaluate compute options for deployment |
| Deploy a model as a service | - configure deployment settings - deploy a registered model - deploy a model trained in Azure Databricks to an Azure Machine Learning endpoint - consume a deployed service - troubleshoot deployment container issues |
| Manage models in Azure Machine Learning | - register a trained model - monitor model usage - monitor data drift |
| Create an Azure Machine Learning pipeline for batch inferencing | - configure a ParallelRunStep - configure compute for a batch inferencing pipeline - publish a batch inferencing pipeline - run a batch inferencing pipeline and obtain outputs - obtain outputs from a ParallelRunStep |
| Publish an Azure Machine Learning designer pipeline as a web service | - create a target compute resource - configure an Inference pipeline - consume a deployed endpoint |
| Implement pipelines by using the Azure Machine Learning SDK | - create a pipeline - pass data between steps in a pipeline - run a pipeline - monitor pipeline runs |
NEW QUESTION 113
You need to configure the Feature Based Feature Selection module based on the experiment requirements and datasets.
How should you configure the module properties? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Mutual Information.
The mutual information score is particularly useful in feature selection because it maximizes the mutual information between the joint distribution and target variables in datasets with many dimensions.
Box 2: MedianValue
MedianValue is the feature column, , it is the predictor of the dataset.
Scenario: The MedianValue and AvgRoomsinHouse columns both hold data in numeric format. You need to select a feature selection algorithm to analyze the relationship between the two columns in more detail.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/filter-based-feature-selection
NEW QUESTION 114
You need to define a modeling strategy for ad response.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation
Step 1: Implement a K-Means Clustering model
Step 2: Use the cluster as a feature in a Decision jungle model.
Decision jungles are non-parametric models, which can represent non-linear decision boundaries.
Step 3: Use the raw score as a feature in a Score Matchbox Recommender model The goal of creating a recommendation system is to recommend one or more "items" to "users" of the system.
Examples of an item could be a movie, restaurant, book, or song. A user could be a person, group of persons, or other entity with item preferences.
Scenario:
Ad response rated declined.
Ad response models must be trained at the beginning of each event and applied during the sporting event.
Market segmentation models must optimize for similar ad response history.
Ad response models must support non-linear boundaries of features.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/multiclass-decision-jungle
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/score-matchbox-recommende
Topic 1, Case Study 1
Overview
You are a data scientist in a company that provides data science for professional sporting events. Models will be global and local market data to meet the following business goals:
*Understand sentiment of mobile device users at sporting events based on audio from crowd reactions.
*Access a user's tendency to respond to an advertisement.
*Customize styles of ads served on mobile devices.
*Use video to detect penalty events.
Current environment
Requirements
* Media used for penalty event detection will be provided by consumer devices. Media may include images and videos captured during the sporting event and snared using social media. The images and videos will have varying sizes and formats.
* The data available for model building comprises of seven years of sporting event media. The sporting event media includes: recorded videos, transcripts of radio commentary, and logs from related social media feeds feeds captured during the sporting events.
*Crowd sentiment will include audio recordings submitted by event attendees in both mono and stereo Formats.
Advertisements
* Ad response models must be trained at the beginning of each event and applied during the sporting event.
* Market segmentation nxxlels must optimize for similar ad resporr.r history.
* Sampling must guarantee mutual and collective exclusivity local and global segmentation models that share the same features.
* Local market segmentation models will be applied before determining a user's propensity to respond to an advertisement.
* Data scientists must be able to detect model degradation and decay.
* Ad response models must support non linear boundaries features.
* The ad propensity model uses a cut threshold is 0.45 and retrains occur if weighted Kappa deviates from 0.1
+/-5%.
* The ad propensity model uses cost factors shown in the following diagram:
The ad propensity model uses proposed cost factors shown in the following diagram:
Performance curves of current and proposed cost factor scenarios are shown in the following diagram:
Penalty detection and sentiment
Findings
*Data scientists must build an intelligent solution by using multiple machine learning models for penalty event detection.
*Data scientists must build notebooks in a local environment using automatic feature engineering and model building in machine learning pipelines.
*Notebooks must be deployed to retrain by using Spark instances with dynamic worker allocation
*Notebooks must execute with the same code on new Spark instances to recode only the source of the data.
*Global penalty detection models must be trained by using dynamic runtime graph computation during training.
*Local penalty detection models must be written by using BrainScript.
* Experiments for local crowd sentiment models must combine local penalty detection data.
* Crowd sentiment models must identify known sounds such as cheers and known catch phrases. Individual crowd sentiment models will detect similar sounds.
* All shared features for local models are continuous variables.
* Shared features must use double precision. Subsequent layers must have aggregate running mean and standard deviation metrics Available.
segments
During the initial weeks in production, the following was observed:
*Ad response rates declined.
*Drops were not consistent across ad styles.
*The distribution of features across training and production data are not consistent.
Analysis shows that of the 100 numeric features on user location and behavior, the 47 features that come from location sources are being used as raw features. A suggested experiment to remedy the bias and variance issue is to engineer 10 linearly uncorrected features.
Penalty detection and sentiment
*Initial data discovery shows a wide range of densities of target states in training data used for crowd sentiment models.
*All penalty detection models show inference phases using a Stochastic Gradient Descent (SGD) are running too stow.
*Audio samples show that the length of a catch phrase varies between 25%-47%, depending on region.
*The performance of the global penalty detection models show lower variance but higher bias when comparing training and validation sets. Before implementing any feature changes, you must confirm the bias and variance using all training and validation cases.
NEW QUESTION 115
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
NEW QUESTION 116
You are using a decision tree algorithm. You have trained a model that generalizes well at a tree depth equal to
10.
You need to select the bias and variance properties of the model with varying tree depth values.
Which properties should you select for each tree depth? To answer, select the appropriate options in the answer area.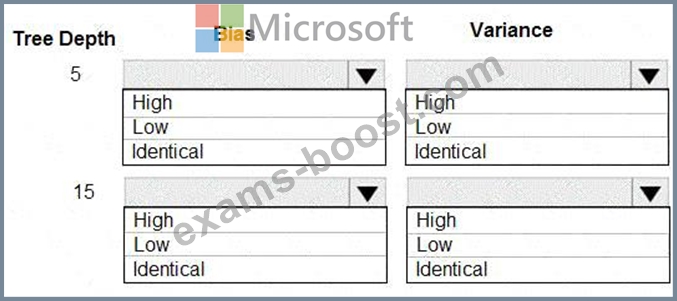
Answer:
Explanation:
Explanation
In decision trees, the depth of the tree determines the variance. A complicated decision tree (e.g. deep) has low bias and high variance.
Note: In statistics and machine learning, the bias-variance tradeoff is the property of a set of predictive models whereby models with a lower bias in parameter estimation have a higher variance of the parameter estimates across samples, and vice versa. Increasing the bias will decrease the variance. Increasing the variance will decrease the bias.
References:
https://machinelearningmastery.com/gentle-introduction-to-the-bias-variance-trade-off-in-machine-learning/
NEW QUESTION 117
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You create an Azure Machine Learning service datastore in a workspace. The datastore contains the following files:
* /data/2018/Q1 .csv
* /data/2018/Q2.csv
* /data/2018/Q3.csv
* /data/2018/Q4.csv
* /data/2019/Q1.csv
All files store data in the following format:
id,M,f2,l
1,1,2,0
2,1,1,1
32,10
You run the following code:
You need to create a dataset named training_data and load the data from all files into a single data frame by using the following code:
Solution: Run the following code:
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 118
You are producing a multiple linear regression model in Azure Machine Learning Studio.
Several independent variables are highly correlated.
You need to select appropriate methods for conducting effective feature engineering on all the data.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation
Step 1: Use the Filter Based Feature Selection module
Filter Based Feature Selection identifies the features in a dataset with the greatest predictive power.
The module outputs a dataset that contains the best feature columns, as ranked by predictive power. It also outputs the names of the features and their scores from the selected metric.
Step 2: Build a counting transform
A counting transform creates a transformation that turns count tables into features, so that you can apply the transformation to multiple datasets.
Step 3: Test the hypothesis using t-Test
References:
https://docs.microsoft.com/bs-latn-ba/azure/machine-learning/studio-module-reference/filter-based-feature-selec
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/build-counting-transform
NEW QUESTION 119
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are using Azure Machine Learning to run an experiment that trains a classification model.
You want to use Hyperdrive to find parameters that optimize the AUC metric for the model. You configure a HyperDriveConfig for the experiment by running the following code:
You plan to use this configuration to run a script that trains a random forest model and then tests it with validation data. The label values for the validation data are stored in a variable named y_test variable, and the predicted probabilities from the model are stored in a variable named y_predicted.
Solution: Run the following code:
Does the solution meet the goal?
- A. Yes
- B. No
Answer: A
NEW QUESTION 120
You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
Box 1: 500
For Random seed, type a value to use as seed for randomization. If you specify 0 (the default), a number is generated based on the system clock.
A seed value is optional, but you should provide a value if you want reproducibility across runs of the same experiment.
Here we must replicate the findings.
Box 2: Mean Absolute Error
Scenario: Given a trained model and a test dataset, you must compute the Permutation Feature Importance scores of feature variables. You need to set up the Permutation Feature Importance module to select the correct metric to investigate the model's accuracy and replicate the findings.
Regression. Choose one of the following: Precision, Recall, Mean Absolute Error , Root Mean Squared Error, Relative Absolute Error, Relative Squared Error, Coefficient of Determination References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/permutation-feature-importan
NEW QUESTION 121
You plan to deliver a hands-on workshop to several students. The workshop will focus on creating data visualizations using Python. Each student will use a device that has internet access.
Student devices are not configured for Python development. Students do not have administrator access to install software on their devices. Azure subscriptions are not available for students.
You need to ensure that students can run Python-based data visualization code.
Which Azure tool should you use?
- A. Azure BatchAl
- B. Azure Machine Learning Service
- C. Anaconda Data Science Platform
- D. Azure Notebooks
Answer: D
Explanation:
Explanation
References:
https://notebooks.azure.com/
NEW QUESTION 122
You are solving a classification task.
You must evaluate your model on a limited data sample by using k-fold cross-validation. You start by configuring a k parameter as the number of splits.
You need to configure the k parameter for the cross-validation.
Which value should you use?
- A. k=1
- B. k=0.5
- C. k=0.01
- D. k=5
Answer: D
Explanation:
Leave One Out (LOO) cross-validation
Setting K = n (the number of observations) yields n-fold and is called leave-one out cross-validation (LOO), a special case of the K-fold approach.
LOO CV is sometimes useful but typically doesn't shake up the data enough. The estimates from each fold are highly correlated and hence their average can have high variance.
This is why the usual choice is K=5 or 10. It provides a good compromise for the bias-variance tradeoff.
Perform Feature Engineering
Testlet 1
Case study
Overview
You are a data scientist in a company that provides data science for professional sporting events. Models will use global and local market data to meet the following business goals:
* Understand sentiment of mobile device users at sporting events based on audio from crowd reactions.
* Assess a user's tendency to respond to an advertisement.
* Customize styles of ads served on mobile devices.
* Use video to detect penalty events
Current environment
* Media used for penalty event detection will be provided by consumer devices. Media may include images and videos captured during the sporting event and shared using social media. The images and videos will have varying sizes and formats.
* The data available for model building comprises of seven years of sporting event media. The sporting event media includes; recorded video transcripts or radio commentary, and logs from related social media feeds captured during the sporting events.
* Crowd sentiment will include audio recordings submitted by event attendees in both mono and stereo formats.
Penalty detection and sentiment
* Data scientists must build an intelligent solution by using multiple machine learning models for penalty event detection.
* Data scientists must build notebooks in a local environment using automatic feature engineering and model building in machine learning pipelines.
* Notebooks must be deployed to retrain by using Spark instances with dynamic worker allocation.
* Notebooks must execute with the same code on new Spark instances to recode only the source of the data.
* Global penalty detection models must be trained by using dynamic runtime graph computation during training.
* Local penalty detection models must be written by using BrainScript.
* Experiments for local crowd sentiment models must combine local penalty detection data.
* Crowd sentiment models must identify known sounds such as cheers and known catch phrases. Individual crowd sentiment models will detect similar sounds.
* All shared features for local models are continuous variables.
* Shared features must use double precision. Subsequent layers must have aggregate running mean and standard deviation metrics available.
Advertisements
During the initial weeks in production, the following was observed:
* Ad response rated declined.
* Drops were not consistent across ad styles.
* The distribution of features across training and production data are not consistent Analysis shows that, of the 100 numeric features on user location and behavior, the 47 features that come from location sources are being used as raw features. A suggested experiment to remedy the bias and variance issue is to engineer 10 linearly uncorrelated features.
* Initial data discovery shows a wide range of densities of target states in training data used for crowd sentiment models.
* All penalty detection models show inference phases using a Stochastic Gradient Descent (SGD) are running too slow.
* Audio samples show that the length of a catch phrase varies between 25%-47% depending on region
* The performance of the global penalty detection models shows lower variance but higher bias when comparing training and validation sets. Before implementing any feature changes, you must confirm the bias and variance using all training and validation cases.
* Ad response models must be trained at the beginning of each event and applied during the sporting event.
* Market segmentation models must optimize for similar ad response history.
* Sampling must guarantee mutual and collective exclusively between local and global segmentation models that share the same features.
* Local market segmentation models will be applied before determining a user's propensity to respond to an advertisement.
* Ad response models must support non-linear boundaries of features.
* The ad propensity model uses a cut threshold is 0.45 and retrains occur if weighted Kappa deviated from
0.1 +/- 5%.
* The ad propensity model uses cost factors shown in the following diagram:
* The ad propensity model uses proposed cost factors shown in the following diagram:
* Performance curves of current and proposed cost factor scenarios are shown in the following diagram:
NEW QUESTION 123
You create a script for training a machine learning model in Azure Machine Learning service.
You create an estimator by running the following code:
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Yes
Parameter source_directory is a local directory containing experiment configuration and code files needed for a training job.
Box 2: Yes
script_params is a dictionary of command-line arguments to pass to the training script specified in entry_script.
Box 3: No
Box 4: Yes
The conda_packages parameter is a list of strings representing conda packages to be added to the Python environment for the experiment.
NEW QUESTION 124
You create a script that trains a convolutional neural network model over multiple epochs and logs the validation loss after each epoch. The script includes arguments for batch size and learning rate.
You identify a set of batch size and learning rate values that you want to try.
You need to use Azure Machine Learning to find the combination of batch size and learning rate that results in the model with the lowest validation loss.
What should you do?
- A. Run the script in an experiment based on an AutoMLConfig object
- B. Run the script in an experiment based on a HyperDriveConfig object
- C. Use the Automated Machine Learning interface in Azure Machine Learning studio
- D. Create a PythonScriptStep object for the script and run it in a pipeline
- E. Run the script in an experiment based on a ScriptRunConfig object
Answer: B
Explanation:
Box 1: import pytorch as deeplearninglib
Box 2: ..DistributedSampler(Sampler)..
DistributedSampler(Sampler):
Sampler that restricts data loading to a subset of the dataset.
It is especially useful in conjunction with class:`torch.nn.parallel.DistributedDataParallel`. In such case, each process can pass a DistributedSampler instance as a DataLoader sampler, and load a subset of the original dataset that is exclusive to it.
Scenario: Sampling must guarantee mutual and collective exclusively between local and global segmentation models that share the same features.
Box 3: optimizer = deeplearninglib.train. GradientDescentOptimizer(learning_rate=0.10) Incorrect Answers: ..SGD..
Scenario: All penalty detection models show inference phases using a Stochastic Gradient Descent (SGD) are running too slow.
Box 4: .. nn.parallel.DistributedDataParallel..
DistributedSampler(Sampler): The sampler that restricts data loading to a subset of the dataset.
It is especially useful in conjunction with :class:`torch.nn.parallel.DistributedDataParallel`.
References:
https://github.com/pytorch/pytorch/blob/master/torch/utils/data/distributed.py Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-tune-hyperparameters
NEW QUESTION 125
You are creating a new experiment in Azure Machine Learning Studio. You have a small dataset that has missing values in many columns. The data does not require the application of predictors for each column. You plan to use the Clean Missing Data.
You need to select a data cleaning method.
Which method should you use?
- A. Synthetic Minority Oversampling Technique (SMOTE)
- B. Normalization
- C. Replace using MICE
- D. Replace using Probabilistic PCA
Answer: D
Explanation:
Replace using Probabilistic PCA: Compared to other options, such as Multiple Imputation using Chained Equations (MICE), this option has the advantage of not requiring the application of predictors for each column.
Instead, it approximates the covariance for the full dataset. Therefore, it might offer better performance for datasets that have missing values in many columns.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
NEW QUESTION 126
You are building a regression model tot estimating the number of calls during an event.
You need to determine whether the feature values achieve the conditions to build a Poisson regression model.
Which two conditions must the feature set contain? I ach correct answer presents part of the solution. NOTE:
Each correct selection is worth one point.
- A. The label data must be non discrete.
- B. The label data mull be a positive value
- C. The label data can be positive or negative,
- D. The label data must be a negative value.
- E. The data must be whole numbers.
Answer: A,B
NEW QUESTION 127
You are building an intelligent solution using machine learning models.
The environment must support the following requirements:
* Data scientists must build notebooks in a cloud environment
* Data scientists must use automatic feature engineering and model building in machine learning
* pipelines.
* Notebooks must be deployed to retrain using Spark instances with dynamic worker allocation.
* Notebooks must be exportable to be version controlled locally.
You need to create the environment.
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation
Step 1: Create an Azure HDInsight cluster to include the Apache Spark Mlib library Step 2: Install Microsot Machine Learning for Apache Spark You install AzureML on your Azure HDInsight cluster.
Microsoft Machine Learning for Apache Spark (MMLSpark) provides a number of deep learning and data science tools for Apache Spark, including seamless integration of Spark Machine Learning pipelines with Microsoft Cognitive Toolkit (CNTK) and OpenCV, enabling you to quickly create powerful, highly-scalable predictive and analytical models for large image and text datasets.
Step 3: Create and execute the Zeppelin notebooks on the cluster
Step 4: When the cluster is ready, export Zeppelin notebooks to a local environment.
Notebooks must be exportable to be version controlled locally.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-zeppelin-notebook
https://azuremlbuild.blob.core.windows.net/pysparkapi/intro.html
NEW QUESTION 128
You need to set up the Permutation Feature Importance module according to the model training requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Accuracy
Scenario: You want to configure hyperparameters in the model learning process to speed the learning phase by using hyperparameters. In addition, this configuration should cancel the lowest performing runs at each evaluation interval, thereby directing effort and resources towards models that are more likely to be successful.
Box 2: R-Squared
NEW QUESTION 129
You are creating a binary classification by using a two-class logistic regression model.
You need to evaluate the model results for imbalance.
Which evaluation metric should you use?
- A. Relative Absolute Error
- B. Root Mean Square Error
- C. Mean Absolute Error
- D. AUC Curve
- E. Accuracy
- F. Relative Squared Error
Answer: D
Explanation:
One can inspect the true positive rate vs. the false positive rate in the Receiver Operating Characteristic (ROC) curve and the corresponding Area Under the Curve (AUC) value. The closer this curve is to the upper left corner, the better the classifier's performance is (that is maximizing the true positive rate while minimizing the false positive rate). Curves that are close to the diagonal of the plot, result from classifiers that tend to make predictions that are close to random guessing.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio/evaluate-model-performance#evaluating-a- binary-classification-model
NEW QUESTION 130
......
How much DP-100 Exam Cost
The price of the DP-100 exam is $165 USD.
Latest 2022 Realistic Verified DP-100 Dumps: https://testking.exams-boost.com/DP-100-valid-materials.html